Trusted by Leading Enterprises


The comprehensive testing and evaluation platform for production AI. BreezeML's adaptive testing agent learns from your specific services and failures, delivering exhaustive coverage across RAG pipelines, agents, and chatbots with cost-efficient evaluation—so enterprises can deploy AI faster and with confidence.
Trusted by Leading Enterprises
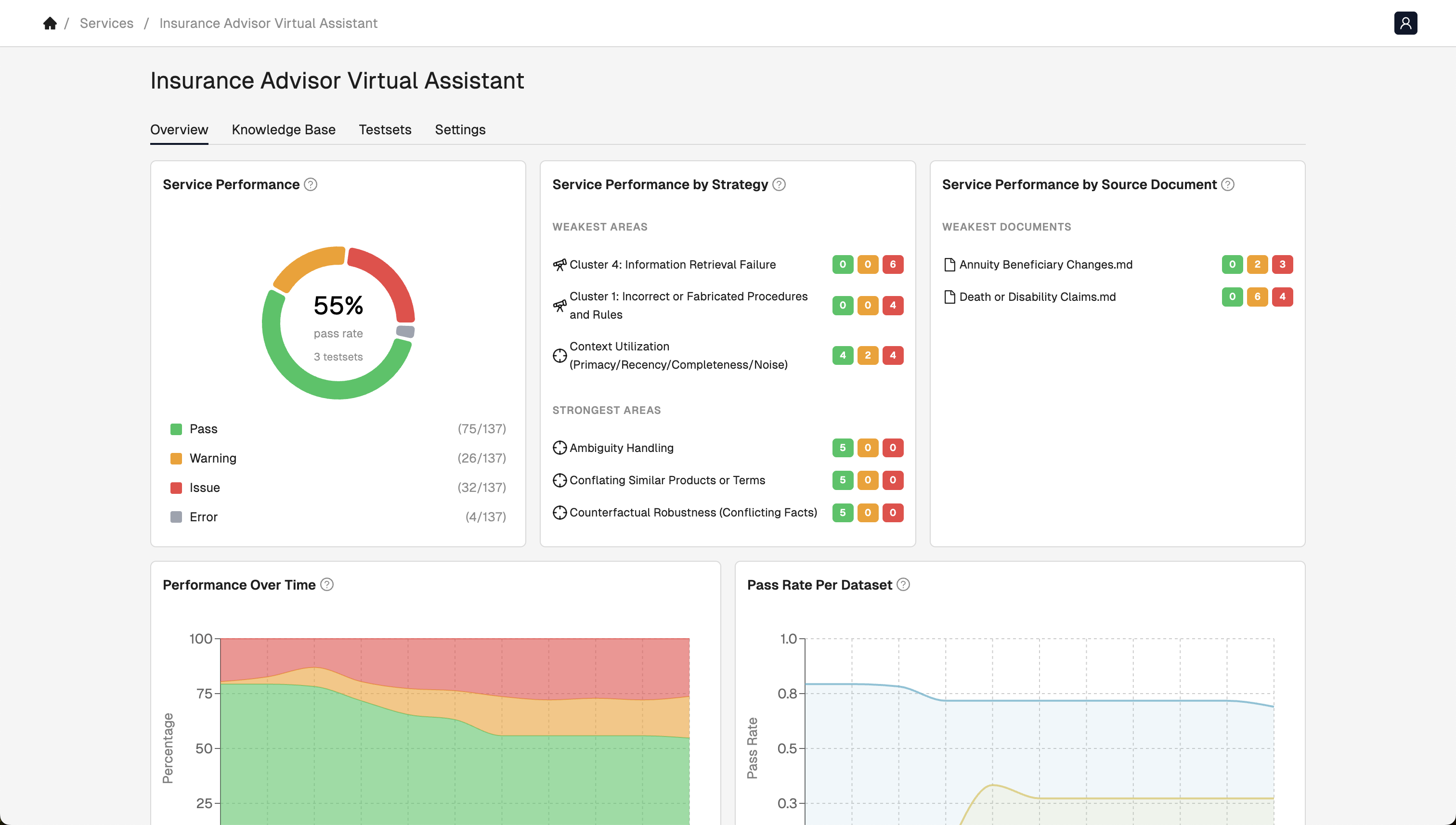
The Breeze platform automatically generates targeted and tailored test sets to evaluate each AI use case for common and edge case failure modes. High-quality, use case-specific tests are the critical pathway to effective guardrails and evaluations—yet manual testing cannot achieve this at scale given the vast, unbounded space of potential inputs, outputs, and failure modes. Guided by first principles, our platform identifies failure modes unique to your implementation, delivering the comprehensive coverage that manual efforts inevitably miss.
Specialized testing for RAG systems, agentic workflows, and conversational AI—from single-turn queries to complex multi-agent orchestration.
Our testing agent learns from your specific services and failure patterns, automatically scaling coverage and intelligently focusing on problematic areas—maximizing utility per test for cost-efficient evaluation.
Move beyond pass/fail metrics with detailed explanations of failures and actionable mitigations: guardrails, data cleanup, prompt optimization, and pipeline tuning like RAG configuration.
Track the metrics enterprises care about: accuracy, hallucination rates, relevance scores, and custom KPIs tailored to your specific use case and business requirements.
Seamlessly integrate into existing development workflows with APIs, webhooks, and native integrations for popular MLOps platforms.
Detect data drift and performance degradation in production with automated alerts. Rerun tests as data or development changes, or generate new tests as your systems evolve.
BreezeML delivers the testing rigor that financial services, healthcare, and enterprise technology companies demand. Our platform provides comprehensive quality assurance needed for mission-critical AI deployments.
Maximum flexibility with deployment options designed for enterprise security and compliance requirements.
Fully managed with zero infrastructure overhead
Complete data sovereignty and control
Native support for AWS, Azure, and GCP
Join financial services leaders and enterprise technology companies using BreezeML to deploy AI with confidence. Available as SaaS or on-premise deployment.
Fill out the form below and our team will reach out to discuss how BreezeML can accelerate your AI deployment.